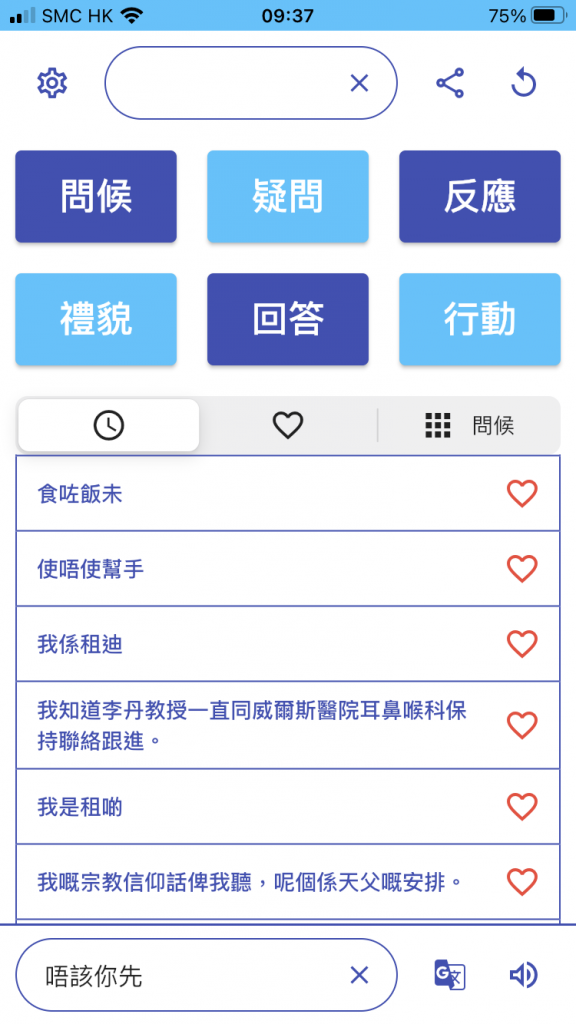
The research team has developed a personalised Chinese text-to-speech system (TTS) to reproduce and “clone” users’ own voices with AI speech technology. The team started with data collection by making recordings with users, covering daily spoken Cantonese materials. These recordings, including their commonly used linguistic and speech characteristics, phrasing, and collocations, are learnt by AI model to construct the speech synthesis model. Patients who lose their speaking ability can benefit from it. Users can type the content that they intend to say and the system will generate speech in the user’s own voice.
Recording user’s speech with diverse content is a critical step in this technology
Uniqueness and Competitive Advantages:
• The technology can largely preserve the user’s voice quality and speaking style
• a mobile app is used to interact with the user
• Patients who lose speaking ability can benefit from the technology
A screen capture of the mobile app for personalized vocie generation. User can either input Chinese characters of desired content or choose pre-loaded text